
1·
1 year agoI’m 99% certain this is wrong
? This is how Postgres stores data, as documents, on the local filesystem:
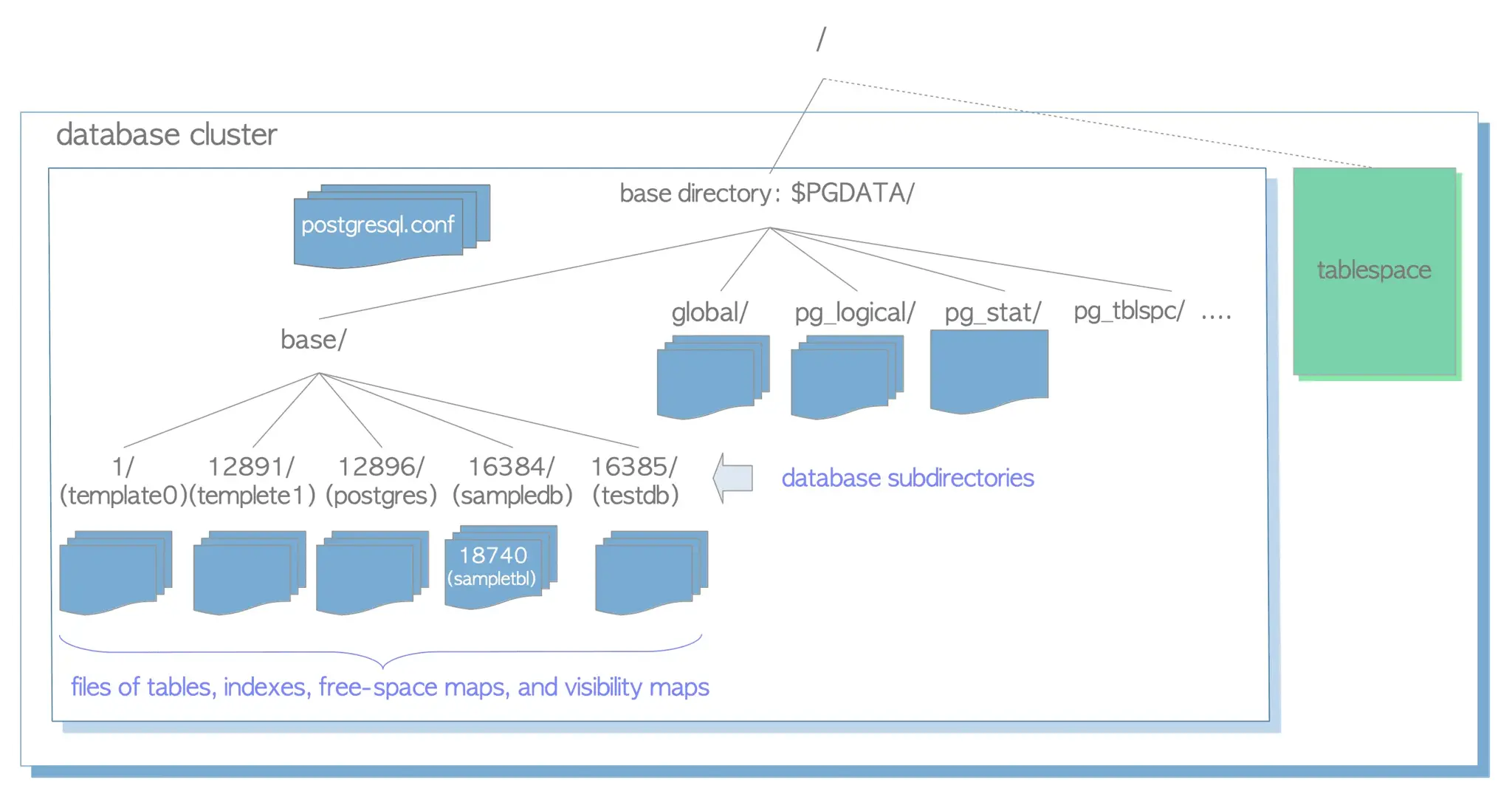
There are hundreds, even thousands, of documents in a typical Postgres database. And similar for other databases.
But anyway, the other side of the issue is more problematic. Converting relational data to, for example, a HTTP response.
Persisting data as documents would be atrocious for performance.
Yep… it’s pretty easy to write a query on a moderately large database that returns 1kb of data and takes five minutes to execute. You won’t have that issue if your 1kb is a simple file on disk. It’ll read in a millisecond.
Yep — that is what I mean by documents, and it’s what I meant all along. The beauty of documents is how simple and flexible they are. Here’s a URL (or path), and here’s the contents of that URL. Done.
No, because you can’t store “literally anything” in a Postgres database. You can only store data that matches the structure of the database. And the structure is also limited, it has to be carefully designed or else it will fall over (e.g. if you put an index on this column, inserts will be too slow, if you don’t have an index on that column selects will be too slow, if you join these two tables the server will run out of memory, if you store these columns redundantly to avoid a join the server will run out of disk space…)
Sure - you can absolutely screw up and design a system where you need to read millions of files to find the one you’re looking for, but because it’s so flexible you should be able to design something efficient easily.
I’m definitely not saying documents should be used for everything. But I am saying they should be used a lot more than they are now. It’s so easy to just write up the schema for a few tables and columns, hit migrate, and presto! You’ve got a data storage system that works well. Often it stops working well a year later when users have spent every day filling it with data.
What I’m advocating is stop, and think, should this be in a relational database or would a document work better? A document is always more work in the short term, you need to carefully design every step of the process… but in the long term it’s often less work.
Almost everything I work with these days is a hybrid - with a combination of relational and document storage. And often the data started in the relational database and had to be moved out because we couldn’t figure out how to make it performant with large data sets.
Also, I’m leaning more and more into using sqlite, with multiple relational databases instead of just a single database. Often I’m treating that database as a document. And I’m not alone, Sqlite is very widely used. Document storage is very widely used. They’re popular because they work and if you are never using them, then I’d suggest you’re probably compromising the quality of your software.